论文名称:《Squeeze-and-Excitation Networks》
论文地址:https://arxiv.org/pdf/1709.01507.pdf
代码地址: https://github.com/hujie-frank/SENet
卷积神经网络 (CNN) 的核心构建块是卷积运算符,它使网络能够通过在每一层的局部感受野中融合空间和通道信息,构建有用的特征。大量的先前研究已经探讨了这种关系的空间部分,旨在通过增强整个特征层次结构中的空间编码质量来加强 CNN 的表现能力。在这项工作中,我们转而关注通道关系,提出了一种新的结构单元,我们称之为 “Squeeze-and-Excitation” (SE) 块,它通过显式建模通道间的相互依赖关系,自适应地重新校准通道特征响应。我们展示了这些模块可以堆叠在一起,形成非常有效地跨不同数据集进行泛化的 SENet 架构。我们还证明,SE 块可以为现有的最先进 CNN 提供显著的性能改进,代价仅为轻微的计算开销。
Squeeze-and-Excitation 网络是我们在 ILSVRC 2017 分类提交的基础,该提交获得了第一名,并将 top-5 错误率降低到 2.251%,相较于 2016 年的获奖结果,取得了约 25% 的相对改进。
问题背景
随着深度学习和神经网络的发展,卷积神经网络(CNN)在许多视觉任务中取得了巨大成功。这些网络通过卷积操作来提取信息,将空间和通道特征融合在一起。然而,尽管在构建深度和复杂模型方面取得了显著进展,但仍有许多方法试图增强模型的表现力。一些研究集中在空间特征的增强上,而其他研究则试图提高深度网络的稳定性。本文提出了一种新的方式,即通过显式建模通道间的相互关系来增强卷积神经网络的表达能力。
核心概念
这篇文章的核心概念是 “Squeeze-and-Excitation”(简称SE)模块。该模块通过调整每个通道的权重,来实现对通道间依赖关系的建模。SE模块的设计目的是通过动态调整通道权重,增加网络的灵活性,从而提高网络的表现力。它通过两个关键步骤来实现这一目标:挤压和激发。
模块的操作步骤
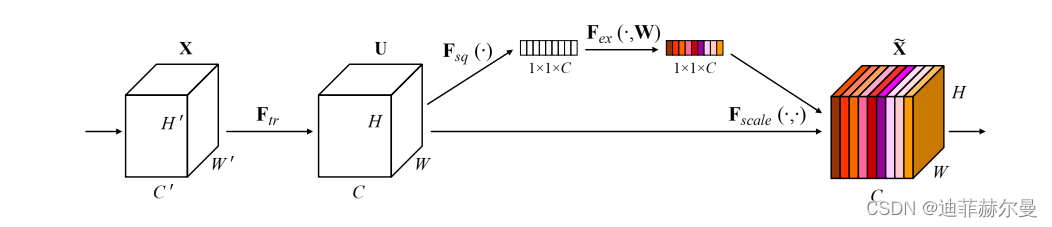
SE模块的操作步骤包括两个主要部分:挤压和激发。在挤压步骤中,模块使用全局平均池化来聚合空间维度,从而生成一个通道描述符。这一操作可以帮助网络获得全局信息,并嵌入通道特征的统计数据。在激发步骤中,模块使用一个简单的门控机制,通过sigmoid激活来调整通道特征。激发操作通过两个全连接层来完成,这两个全连接层之间包含ReLU激活,用于学习通道间的非线性关系。最终,模块会根据激发结果对通道进行重加权,从而实现对特征的动态调整。
文章贡献
本文的主要贡献在于提出了SE模块,并通过将其嵌入到现有的卷积神经网络中,显著提高了网络的表现力。SE模块的设计非常灵活,既可以作为一种新的模块加入网络中,也可以直接替换已有的模块。本文展示了SE模块在不同深度、不同架构的网络中的应用,并证明了其有效性。此外,作者还在ImageNet等著名数据集上进行了实验,显示了SE模块带来的性能提升。
实验结果与应用
实验结果表明,SE模块在多种不同的网络架构中都能带来显著的性能提升。作者通过在ResNet、Inception和其他现代架构中加入SE模块,证明了其普适性和有效性。在ImageNet数据集上的实验结果显示,SE模块可以显著降低错误率,提高准确性。此外,本文还展示了SE模块在其他数据集和任务上的应用,包括场景分类和目标检测,进一步证明了其广泛的适用性。
对未来工作的启示
本文提出的SE模块不仅在提高卷积神经网络的表现力方面取得了成功,而且也为未来的研究提供了启示。首先,SE模块展示了通道间依赖关系的重要性,这可能激发进一步研究在其他领域中应用这一概念。其次,SE模块的设计相对简单,但带来了显著的性能提升,这表明在网络设计中,简单且有效的改进方法仍有很大的潜力。未来的工作可以进一步探索SE模块的其他应用场景,以及如何与其他网络改进技术相结合。
这种模块化的设计理念也可能对神经网络挤压和优化等领域带来启发。通过调整通道权重来优化网络,可以降低模型的复杂性,同时保持或提高性能。这一理念可能对移动设备和嵌入式系统等资源受限的应用领域产生积极影响。
代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SE(nn.Module):
def __init__(self, channel=512, reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid(),
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
if __name__ == "__main__":
input = torch.randn(64, 256, 8, 8)
model = SE(channel=256, reduction=8)
output = model(input)
print(output.shape)